Image to Video Linking
For documentation of endoscopic procedures, surgeons often use still images. These images are recorded and selected by the surgeon during the surgery and play an important role for the quick assessment of a medical case. However, for other purposes (e.g., the training of young surgeons) a video sequence is a better source of information. Thus, surgeons adopted to record and store videos of the entire endoscopic procedure besides a set of still images. However, with the accumulation of vast amounts of video and image data from endoscopic surgeries, manually searching or maintaining links to interesting sections becomes infeasible.
In practice there is no trivial way to interlink captured images and recorded videos. This problem originates from the use of different systems with distinct encoders for images and videos. This introduces encoding differences between still images and video frames (i.e., there is no exact match possible but only a near duplicate exists). Moreover, image and video encoding often run on different systems with unsynchronized clocks, which reduces the applicability of temporal correlation. As a result, current systems do not provide the functionality to automatically link captured images to the appropriate video positions. Consequently, it is a time-consuming task for surgeons to brows large multimedia databases of endoscopic videos manually in order to find and maintain links between images and video sequences. To cope with this issue recent research [1-3] has addressed how to automatically perform image to video linking for endoscopic surgeries.
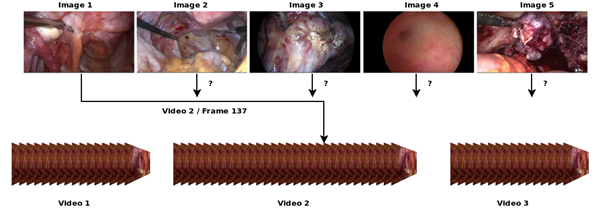
Our goal is to enable surgeons to quickly access relevant surgery scenes within a large video database by providing a reference image, showing the desired content of the scene (query by example). Achieving this goal includes completing two tasks: (1) retrieve the correct video that contains the given scene and (2) if such a video exists, get the correct position within the video. Thus, the results of a successful query are the video id and the presentation timestamp, so that the desired video segment can be retrieved quickly.
Recently, the field of computer vision has made significant advances by using deep learning mechanisms, such as Convolutional Neural Networks (CNN) for image analysis [4]. In traditional approaches experts manually created features that represent information about an image (e.g., shapes, textures, colors). In contrast, when using a CNN for image analysis, the features are automatically created by the neural network during the learning phase. Since training a large CNN is a resource intensive task which also requires a large training set of labelled data, researchers had the idea to use the extracted features of a well-trained CNN, so called “off-the-shelf CNN features”, for different image analysis tasks. Results suggest that the features from CNN perform very well in most visual recognition tasks [5].
Off-the-shelf CNN features have proven to be a good choice for the content-based description of images. However, they are high-dimensional descriptors consisting of real values and have the drawback of consuming huge amounts of storage space (about 5.5% of the video data). Thus, our goal is to reduce storage requirements dramatically by quantizing the feature values without affecting the retrieval performance significantly. In particular, we use basic statistical methods in order to encode off-the-shelf CNN features into quantized vectors of the same dimension.
We use extracted features from the AlexNet CNN as image descriptors. In particular, we extract these features from the last three layers of the AlexNet architecture (i.e., from fc6, fc7 and fc8, which we further will denote as HoCC). Each feature is an n-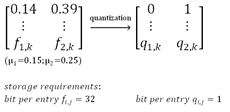 dimensional vector (where n=4096 for fc6 and fc7 and n=1000 for HoCC). Based on the features for a set of given endoscopic videos, we calculate the average value for each feature component. To generate a quantized version of this feature set we assign each feature component the value ‘0’ if it is smaller than the average value of the respective average or ‘1’ otherwise. Thus, each feature component now is represented only by a single binary value. Compared to the original representation using 32 bit real values, the quantized form uses only 1 bit per value.
dimensional vector (where n=4096 for fc6 and fc7 and n=1000 for HoCC). Based on the features for a set of given endoscopic videos, we calculate the average value for each feature component. To generate a quantized version of this feature set we assign each feature component the value ‘0’ if it is smaller than the average value of the respective average or ‘1’ otherwise. Thus, each feature component now is represented only by a single binary value. Compared to the original representation using 32 bit real values, the quantized form uses only 1 bit per value.
We performed a series of evaluations to assess the performance of our approach using quantized off-the-shelf features to several baseline approaches: pixel-based comparison (PSNR), image structure comparison (SSIM), hand-crafted global features (CEDD and feature signatures). Additionally, we compare our approach to the unmodified off-the-shelf CNN features (fc6, fc7 and HoCC), in order to assess how quantization affects the retrieval performance. We also compare the performance of the CNN-based approaches using difference distance metrics (i.e., Manhattan, Euclidean and Max distance). For all evaluations we use a test set consisting of 69 query images and over five hours of video recordings from gynaecological interventions. As performance metrics we use video hit rate, i.e. the fraction of queries that was linked to the correct video and the average offset between the retrieved position and the correct presentation timestamp (avg. delta).

Our evaluation shows that state-of-the art methods have severe drawbacks in this task. Although, PSNR and SSIM provide a solid baseline, they are computationally not feasible for large multimedia databases. The content descriptor CEDD and feature signatures do not have these problems. However, they perform worse than PSNR, especially at dense and high sampling rates. The performance of our proposed approach using quantized off-the-shelf features only suffers from a slight performance decline, compared to the uncompressed CNN features. It reaches and partially outperforms the performance of other approaches (e.g. feature signatures) at sparse sampling intervals. We assume that the quantization is beneficial for feature abstraction. Furthermore, quantized features reduce the storage space requirement by a factor of 32 compared to uncompressed off-the-shelf features. Future work in this topic may consider reducing the dimensionality of the already quantized features. Furthermore, for future work we aim at automatically detect the boundaries of the relevant surgery scenes automatically.
References
- C. Beecks, K. Schoeffmann, M. Lux, M. S. Uysal and T. Seidl, “Endoscopic Video Retrieval: A Signature-Based Approach for Linking Endoscopic Images with Video Segments,” IEEE International Symposium on Multimedia, 2015, pp. 33-38.
- J. R. Carlos, M. Lux, X. Giro-i-Nieto, P. Munoz and N. Anagnostopoulos, “Visual information retrieval in endoscopic video archives,” 13th Int. Workshop on Content-Based Multimedia Indexing (CBMI), 2015 pp. 1-6.
- S. Petscharnig, “Semi-Automatic Retrieval of Relevant Segments from Laparoscopic Surgery Videos,” Proc. of the ACM Int. Conf. on Multimedia Retrieval, 2017, pp. 484-488.
- A. Krizhevsky, I. Sutskever, G.E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” Advances in Neural Information Processing Systems (NIPS), vol. 25, 2012, pp. 1106–1114.
- A. S. Razavian, H. Azizpour, J. Sullivan and S. Carlsson, “CNN Features Off-the-Shelf: An Astounding Baseline for Recognition,” IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2014, pp. 512-519.